AI agents in production: lessons learned after 18 months
The gap between demo and production
There is a well-documented gap between an AI agent that works in a demo and one that works in production. The demo agent handles the happy path, processes clean inputs, and impresses stakeholders. The production agent handles malformed data, API timeouts, ambiguous instructions, and the full spectrum of real-world entropy. After 18 months of deploying AI agents across logistics, finance, and operations workflows, we have accumulated a set of hard-won lessons about what works, what breaks, and what matters.
The core insight is not technical. It is organizational. AI agents fail in production not because the models are bad, but because the systems around them are not designed for the failure modes that agents introduce. Traditional software fails predictably. Agents fail creatively. And most engineering teams are not prepared for that.
Why agents fail in production
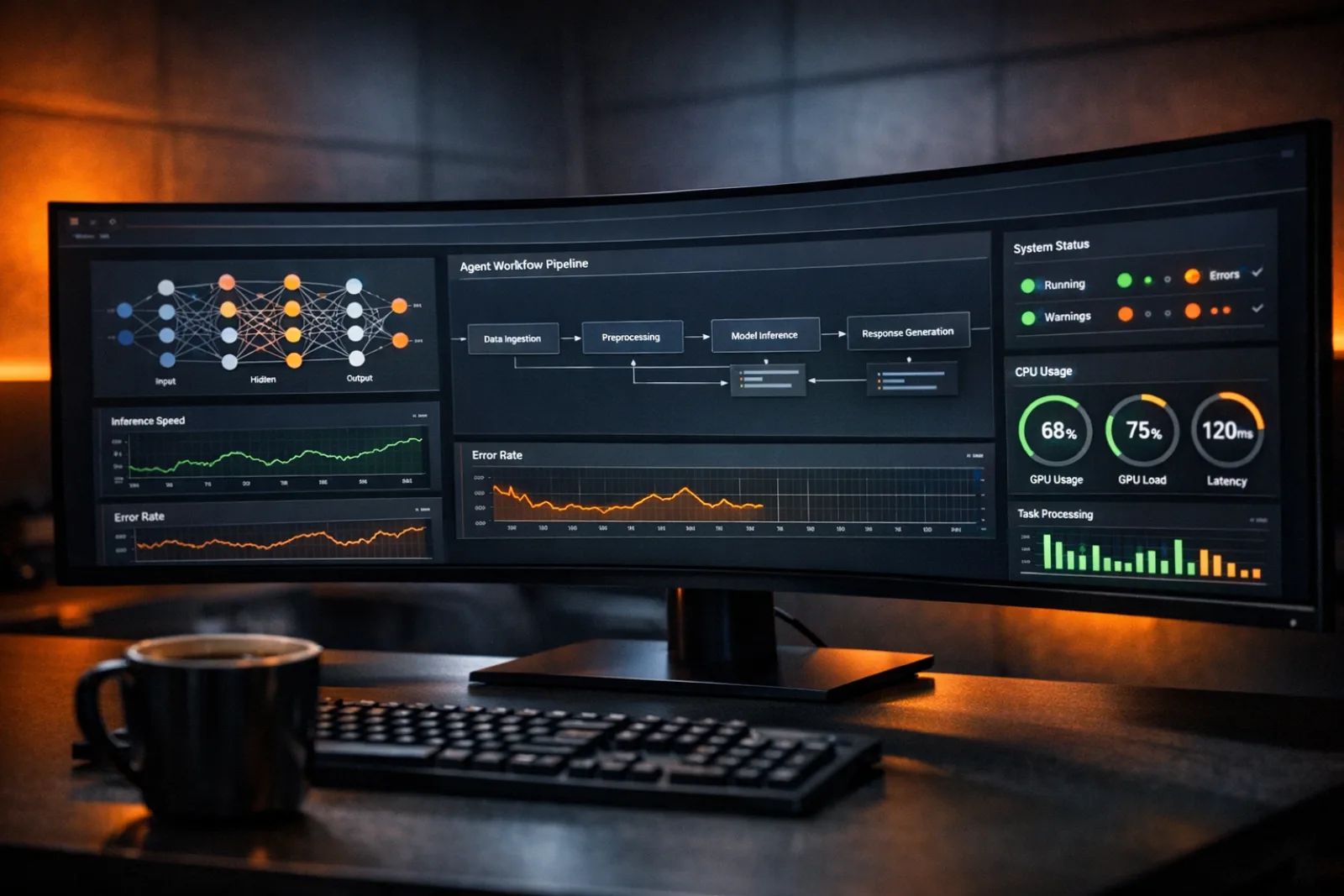
The most common failure pattern we observed is what we call the fragile chain problem. An agent that chains four or five tool calls together to complete a task has a compounding failure rate. If each step has a 95% success rate, the chain succeeds roughly 77% of the time. At 90% per step, you are down to 59%. Those numbers are unacceptable for business-critical workflows, and most teams discover this only after deployment.
The second failure mode is uncontrolled costs. LLM inference is not free, and agents that reason through complex tasks can burn through token budgets rapidly. We had one early agent that processed shipping exceptions. It worked well for standard cases at roughly $0.02 per invocation. Then it encountered an edge case that triggered a reasoning loop: the agent kept re-reading the same document, trying different interpretations, burning through $4.50 on a single request before we killed it. Without token budgets and circuit breakers, one bad input can blow your monthly spend in hours.
The third failure mode is silent degradation. Unlike a REST API that returns a 500 error, an agent can return a plausible but wrong answer. It parses an invoice incorrectly, extracts the wrong amount, assigns the wrong category. The output looks valid. Nobody notices until the accountant reconciles at month-end and finds thirty misclassified entries. Without quality metrics and sampling-based evaluation, you are flying blind.
Lack of observability compounds all three problems. Most teams log the final output of an agent but not the intermediate reasoning steps. When something goes wrong, there is no trace to follow. You know the agent produced a bad result, but you have no idea why.
Architecture patterns that work
After iterating through several architectures, we settled on a set of patterns that have proven reliable.
Supervisor pattern. Instead of a single monolithic agent, we use a lightweight supervisor that orchestrates specialized sub-agents. The supervisor handles routing, error recovery, and state management. Each sub-agent is scoped to a specific capability: one reads documents, another queries APIs, another generates structured outputs. This decomposition makes each component testable and replaceable. It also limits the blast radius of failures. If the document reader fails, the supervisor can retry or fall back without losing the entire workflow state.
Human-in-the-loop with confidence thresholds. Not every decision needs human review, but not every decision should be autonomous either. We assign confidence scores to agent outputs. Outputs above the high threshold proceed automatically. Outputs below the low threshold are rejected and queued for manual processing. Outputs in the middle go to a human review queue. The thresholds are calibrated per use case and adjusted based on observed error rates. This gives us the throughput of automation with the safety net of human judgment where it matters.
Graceful degradation. Every agent has a fallback path that does not involve the LLM. If the model is unavailable, if the token budget is exhausted, if the response fails validation, the system falls back to a rule-based handler or queues the task for manual processing. The business process never stops. It may slow down, but it never breaks. This is a non-negotiable design principle.
Structured outputs with validation. We moved away from free-form text responses early on. Every agent produces structured output validated against a JSON schema or a Pydantic model. If the output does not conform, it is rejected and retried. This eliminates an entire category of parsing errors and makes downstream processing deterministic. Tools like OpenAI’s structured outputs and Anthropic’s tool calling make this straightforward to implement.
Observability for agents
Traditional APM tools are insufficient for agent observability. You need traces that capture the full reasoning chain: the initial prompt, each tool call with its arguments and response, the intermediate reasoning, and the final output. We built our observability layer on three pillars.
Chain tracing. Every agent invocation gets a trace ID that follows the request through every sub-agent, tool call, and LLM interaction. We use OpenTelemetry spans to capture each step with its latency, token usage, and result. When an agent produces a bad output, we can reconstruct exactly what happened at each step. This is the single most valuable debugging tool we have.
Token usage monitoring. We track token consumption per agent, per user, per workflow. We set budgets at the invocation level (no single request can exceed N tokens), at the hourly level (circuit breaker if spend exceeds threshold), and at the monthly level (alerting and automatic throttling). The budgets are enforced in the supervisor layer, not in the agents themselves. This is important because individual agents should not be responsible for cost management.
Quality metrics. We sample agent outputs and evaluate them against ground truth. For document extraction tasks, we compare extracted fields against human-verified values. For classification tasks, we track precision and recall on a rolling basis. For generation tasks, we use LLM-as-judge evaluation on a random sample. These metrics feed into dashboards and alerting. If extraction accuracy drops below 94%, we get an alert and can investigate before the error propagates.
We also track operational metrics that are specific to agents: retry rates, fallback rates, human escalation rates, and average chain length. A sudden increase in any of these signals a problem before it becomes visible in output quality.
Cost control strategies
Cost control for AI agents requires discipline at multiple levels. At the model level, we use the cheapest model that meets the quality bar for each task. Classification tasks use smaller models. Complex reasoning uses larger models. We never default to the most capable model out of convenience.
At the prompt level, we invest heavily in prompt engineering to reduce token consumption. Shorter prompts with few-shot examples outperform verbose prompts with extensive instructions in most of our use cases. We cache common prompt fragments and use system prompts efficiently.
At the architecture level, the supervisor pattern enables selective invocation. Not every request needs every sub-agent. The supervisor evaluates the request and activates only the components needed. A simple shipping status query does not trigger the document extraction pipeline.
At the operational level, we maintain cost dashboards per agent and per customer. We bill agent usage as part of our managed services, which means cost efficiency directly affects margin. This creates natural pressure to optimize continuously rather than treating inference costs as an externality.
Lessons that changed how we build
Eighteen months of production operation taught us lessons that no documentation or tutorial covered.
First, determinism matters more than capability. A less capable agent that produces consistent, predictable results is more valuable than a more capable agent with high variance. Business processes need reliability, not brilliance.
Second, evaluation infrastructure should be built before the agent. If you cannot measure whether the agent is working correctly, you should not deploy it. We now build the evaluation pipeline first and the agent second. The evaluation defines the contract that the agent must meet.
Third, agents should be stateless between invocations. All state lives in external storage: databases, queues, object stores. The agent reads the current state, performs its work, and writes the new state. This makes agents horizontally scalable, recoverable after failures, and simple to reason about.
Fourth, the biggest ROI comes from boring automation, not impressive demos. Our most valuable agents handle invoice classification, shipment status updates, and email triage. They are not exciting. They save hundreds of hours per month.
Fifth, plan for the model to change. We have swapped underlying models three times in 18 months as better options became available. Our abstraction layer makes model changes a configuration change, not a rewrite. If your agent code is tightly coupled to a specific model’s API, you are accumulating integration debt that will cost you later.
Building AI agents for production is engineering, not experimentation. It requires the same discipline as any other production system: observability, testing, graceful degradation, and cost management. The model is the easy part. Everything around it is what determines success. For a broader view of the agent ecosystem, see our state of the art of AI agents in 2025. We also document orchestration and failure patterns in a dedicated whitepaper, and detail architecture patterns for autonomous agents in another article.
